Gas optimization best practices
Stylus contracts offer significant gas savings compared to Solidity (10-100x for compute-heavy operations), but following optimization best practices can reduce costs even further.
Why Stylus is cheaper
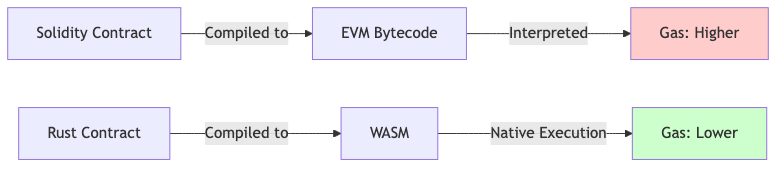
Figure: Stylus WASM executes natively, avoiding EVM interpretation overhead.
Performance comparison
| Operation | Solidity (EVM) | Stylus (WASM) | Savings |
|---|---|---|---|
| Keccak256 hashing | ~30 gas/byte | ~3 gas/byte | 10x |
| Signature verification | ~3,000 gas | ~300 gas | 10x |
| Memory operations | ~3 gas/word | ~0.3 gas/word | 10x |
| Compute-heavy loops | High | Very low | 50-100x |
| Storage operations | Same | Same | 1x |
Key insight: Storage operations cost the same in Stylus and Solidity. Optimize by reducing storage access and maximizing compute efficiency.
Storage optimization
1. Minimize storage reads
// ❌ Bad: Multiple storage reads
pub fn calculate_bad(&self, iterations: u32) -> U256 {
let mut result = U256::ZERO;
for i in 0..iterations {
// Reads from storage every iteration!
result += self.multiplier.get();
}
result
}
// ✅ Good: Cache storage value
pub fn calculate_good(&self, iterations: u32) -> U256 {
// Read once, use many times
let multiplier = self.multiplier.get();
let mut result = U256::ZERO;
for i in 0..iterations {
result += multiplier;
}
result
}
Gas impact: Each storage read costs ~100 gas. The optimized version can save thousands of gas for large loops.
2. Batch storage writes
// ❌ Bad: Multiple separate writes
pub fn update_user_bad(&mut self, addr: Address, amount: U256, active: bool) {
self.balances.setter(addr).set(amount);
self.last_update.setter(addr).set(block::timestamp());
self.is_active.setter(addr).set(active);
}
// ✅ Good: Combine into struct
sol_storage! {
pub struct UserData {
U256 balance;
U256 last_update;
bool is_active;
}
pub struct OptimizedContract {
StorageMap<Address, UserData> users;
}
}
pub fn update_user_good(&mut self, addr: Address, amount: U256, active: bool) {
let mut user = self.users.setter(addr);
user.balance.set(amount);
user.last_update.set(block::timestamp());
user.is_active.set(active);
// Single storage slot update instead of three
}
3. Use appropriate data types
// ❌ Bad: Oversized types
sol_storage! {
pub struct Wasteful {
StorageU256 tiny_counter; // Only needs u8
StorageU256 timestamp; // Only needs u64
StorageU256 percentage; // Only needs u16
}
}
// ✅ Good: Right-sized types
sol_storage! {
pub struct Efficient {
StorageU8 tiny_counter; // Saves 31 bytes
StorageU64 timestamp; // Saves 24 bytes
StorageU16 percentage; // Saves 30 bytes
}
}
Note: While smaller types save storage space, they don't reduce gas for individual storage operations. The benefit comes from packing multiple small values in one slot (if your storage layout supports it).
4. Delete unused storage
pub fn cleanup(&mut self, addr: Address) -> Result<(), Vec<u8>> {
let balance = self.balances.get(addr);
ensure!(balance == U256::ZERO, "Balance not zero");
// ✅ Deleting storage refunds gas
self.balances.delete(addr);
self.metadata.delete(addr);
Ok(())
}
Gas refund: Deleting storage refunds up to 15,000 gas per slot cleared.
Memory optimization
1. Avoid unnecessary clones
use alloy_primitives::Bytes;
// ❌ Bad: Unnecessary cloning
pub fn process_data_bad(&self, data: Bytes) -> Bytes {
let copy = data.clone(); // Expensive memory allocation
copy
}
// ✅ Good: Use references
pub fn process_data_good(&self, data: &Bytes) -> &Bytes {
data // No clone needed
}
// ✅ Good: Move when possible
pub fn consume_data(mut data: Bytes) -> Bytes {
data.extend_from_slice(&[1, 2, 3]);
data // Ownership moved, no clone
}
2. Use iterators efficiently
// ❌ Bad: Collect into vector unnecessarily
pub fn sum_bad(&self, values: Vec<U256>) -> U256 {
let filtered: Vec<U256> = values
.iter()
.filter(|v| **v > U256::ZERO)
.copied()
.collect(); // Allocates new vector
filtered.iter().sum()
}
// ✅ Good: Chain iterators
pub fn sum_good(&self, values: Vec<U256>) -> U256 {
values
.iter()
.filter(|v| **v > U256::ZERO)
.sum() // No intermediate allocation
}
3. Reuse allocations
// ✅ Reuse buffers for repeated operations
pub fn process_batch(&mut self, items: Vec<Bytes>) -> Vec<Bytes> {
let mut buffer = Vec::with_capacity(items.len());
for item in items {
buffer.clear(); // Reuse allocation
buffer.extend_from_slice(&item);
// Process buffer...
}
buffer
}
Computation optimization
1. Use Stylus for compute-heavy operations
// ✅ Stylus excels at complex computation
pub fn verify_merkle_proof(
&self,
leaf: [u8; 32],
proof: Vec<[u8; 32]>,
root: [u8; 32]
) -> bool {
let mut computed_hash = leaf;
// This loop is 10-50x cheaper in Stylus than Solidity
for proof_element in proof {
computed_hash = if computed_hash <= proof_element {
keccak256(&[computed_hash, proof_element].concat())
} else {
keccak256(&[proof_element, computed_hash].concat())
};
}
computed_hash == root
}
Why it's faster: Native WASM execution vs. EVM interpretation makes loops dramatically cheaper.
2. Optimize hot paths
// ✅ Optimize frequently-called functions
#[inline(always)]
pub fn is_valid_amount(&self, amount: U256) -> bool {
amount > U256::ZERO && amount <= self.max_amount.get()
}
// Use in hot path
pub fn transfer(&mut self, to: Address, amount: U256) -> Result<(), Vec<u8>> {
ensure!(self.is_valid_amount(amount), "Invalid amount");
// Transfer logic...
Ok(())
}
3. Avoid redundant checks
// ❌ Bad: Redundant zero check
pub fn add_to_balance_bad(&mut self, addr: Address, amount: U256) -> Result<(), Vec<u8>> {
ensure!(amount > U256::ZERO, "Amount must be positive");
let current = self.balances.get(addr);
ensure!(current + amount > current, "Overflow"); // Redundant if amount > 0
self.balances.setter(addr).add_assign(amount);
Ok(())
}
// ✅ Good: Single overflow check covers both
pub fn add_to_balance_good(&mut self, addr: Address, amount: U256) -> Result<(), Vec<u8>> {
let current = self.balances.get(addr);
let new_balance = current
.checked_add(amount)
.ok_or("Overflow or invalid amount")?;
self.balances.setter(addr).set(new_balance);
Ok(())
}
Function call optimization
1. Minimize cross-contract calls
// ❌ Bad: Multiple external calls
pub fn get_price_bad(&self, token: Address) -> Result<U256, Vec<u8>> {
let oracle = IOracle::new(self.oracle_address.get());
let price = oracle.get_price(self, token)?;
let decimals = oracle.get_decimals(self, token)?; // Second call
let timestamp = oracle.get_timestamp(self, token)?; // Third call
Ok(price)
}
// ✅ Good: Batch external calls
pub fn get_price_good(&self, token: Address) -> Result<PriceData, Vec<u8>> {
let oracle = IOracle::new(self.oracle_address.get());
// Single call returns all data
oracle.get_price_data(self, token)
}
Gas impact: Each external call has overhead. Batching reduces cost significantly.
2. Use internal functions
// ✅ Extract common logic to internal functions
impl MyContract {
// Internal helper (no ABI encoding overhead)
fn internal_validate(&self, addr: Address, amount: U256) -> Result<(), Vec<u8>> {
ensure!(!addr.is_zero(), "Invalid address");
ensure!(amount > U256::ZERO, "Invalid amount");
Ok(())
}
// Public functions use internal helper
#[external]
pub fn deposit(&mut self, amount: U256) -> Result<(), Vec<u8>> {
self.internal_validate(msg::sender(), amount)?;
// Deposit logic...
Ok(())
}
#[external]
pub fn withdraw(&mut self, amount: U256) -> Result<(), Vec<u8>> {
self.internal_validate(msg::sender(), amount)?;
// Withdraw logic...
Ok(())
}
}
Event optimization
1. Use indexed parameters wisely
sol! {
// ✅ Index frequently-queried fields (max 3 indexed)
event Transfer(
address indexed from,
address indexed to,
uint256 value // Not indexed - saves gas
);
// ❌ Bad: Too many indexed parameters
event TooManyIndexed(
address indexed from,
address indexed to,
uint256 indexed amount, // Expensive to index
uint256 indexed timestamp // 4th indexed param - not allowed!
);
}
Gas impact: Each indexed parameter costs ~375 additional gas. Only index fields you'll search by.
2. Batch events when possible
// ✅ Emit single event for batch operation
sol! {
event BatchTransfer(
address indexed from,
address[] to,
uint256[] amounts
);
}
pub fn batch_transfer(
&mut self,
recipients: Vec<Address>,
amounts: Vec<U256>
) -> Result<(), Vec<u8>> {
// Process transfers...
// Single event instead of N events
evm::log(BatchTransfer {
from: msg::sender(),
to: recipients,
amounts,
});
Ok(())
}
Binary size optimization
Smaller WASM binaries cost less to deploy and activate.
1. Optimize compilation flags
# Cargo.toml
[profile.release]
opt-level = "z" # Optimize for size
lto = true # Link-time optimization
codegen-units = 1 # Better optimization
strip = true # Remove debug symbols
panic = "abort" # Smaller panic handling
2. Avoid large dependencies
// ❌ Bad: Heavy dependency for simple task
use fancy_math_library::complex_sqrt; // Adds 50KB to binary
pub fn calculate(&self, value: U256) -> U256 {
complex_sqrt(value) // Using 1% of library
}
// ✅ Good: Implement simple operations yourself
pub fn simple_sqrt(&self, value: U256) -> U256 {
// Custom implementation adds minimal binary size
// Newton's method or similar
}
3. Use cargo stylus optimization
# Check binary size
cargo stylus check
# Optimize with wasm-opt
cargo stylus deploy --optimize
# Maximum optimization (slower build, smaller binary)
cargo stylus deploy --optimize-level 3
Gas measurement
1. Profile your contracts
#[cfg(test)]
mod gas_tests {
use super::*;
#[test]
fn benchmark_transfer() {
let vm = TestVM::default();
let mut contract = Token::from(&vm);
// Measure gas for operation
let gas_before = vm.gas_left();
contract.transfer(recipient, amount).unwrap();
let gas_used = gas_before - vm.gas_left();
println!("Transfer gas used: {}", gas_used);
assert!(gas_used < 50000, "Transfer too expensive");
}
}
2. Compare implementations
#[cfg(test)]
mod optimization_tests {
#[test]
fn compare_storage_patterns() {
// Test pattern A
let gas_a = measure_pattern_a();
// Test pattern B
let gas_b = measure_pattern_b();
println!("Pattern A: {} gas", gas_a);
println!("Pattern B: {} gas", gas_b);
println!("Savings: {}%", (gas_a - gas_b) * 100 / gas_a);
}
}
Optimization checklist
Before deploying, verify you've:
- Minimized storage reads and writes
- Cached frequently-accessed storage values
- Used appropriate data types
- Deleted unused storage for gas refunds
- Avoided unnecessary clones and allocations
- Optimized hot code paths
- Minimized cross-contract calls
- Used indexed events sparingly
- Optimized WASM binary size
- Profiled gas usage for critical functions
- Compared against Solidity baseline (if porting)
Common optimizations summary
| Pattern | Gas Savings | Complexity |
|---|---|---|
| Cache storage reads | High (100+ gas per read saved) | Low |
| Delete unused storage | Medium (15,000 gas refund) | Low |
| Batch storage writes | Medium (varies) | Medium |
| Use iterators vs. collect | Low-Medium | Low |
| Minimize external calls | High | Medium |
| Optimize binary size | High (deployment only) | Medium |
| Right-size data types | Low-Medium | Low |
Advanced optimization
Custom memory allocators
For advanced users, custom allocators can reduce memory overhead:
#[global_allocator]
static ALLOCATOR: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
Warning: Only use if you understand the trade-offs.
Assembly optimization
For critical paths, you can use WASM intrinsics:
use core::arch::wasm32::*;
// ✅ Advanced: Use WASM intrinsics for critical operations
pub fn optimized_hash(&self, data: &[u8]) -> [u8; 32] {
// WASM-optimized hashing
// Only use if you're an advanced developer
}
Next steps
- Apply security best practices
- Study deployment optimization
- Learn about caching strategies
- Review debugging techniques